Atomic Habits
By James Clear | Rating: 4.5/5
A practical framework for building better systems and making tiny improvements stick.

By James Clear | Rating: 4.5/5
A practical framework for building better systems and making tiny improvements stick.
The IITB Mars Rover Team was founded in 2012 with the goal of understanding the science and engineering behind building a rover for the red planet. The team has grown to be a platform for experimentation and production of rover prototypes, similar to how NASA has produced rovers such as the Pathfinder. The team has its own line of 6 rovers that have been upgraded to become more advanced and robust over time.
Short description of portfolio item number 2 
Event Silver · Inter IIT Tech Meet 11.0, Jan 2022
Closed-domain QA on SQuAD-like data with T5/GPT-3 augmentations and a 3× faster DrQA retriever; an Electra-BERT ensemble hit 0.85 F1 with 2.65× runtime improvement via ONNX + quantization.
Research Intern, May–Dec 2023 · with Balaraman Ravindran, RBCDSAI
Developed visual domain adaptation for CARLA using stable-diffusion models conditioned on simulator images with uniform domain randomization, learning a generalized control policy robust to the sim2real gap.
Gold-winning submission · Train Offline Test Online (TOTO) Workshop, NeurIPS 2023
Built DiffClone for offline, sparse-reward robotic control: a MoCo-fine-tuned ResNet-50 encoder + DDPM behaviour-cloning agent reaching a 92% success rate on pouring, surpassing existing benchmarks.
Undergrad Researcher & Executive Head (25-person lab), Jul 2022 – Jul 2024 · with Debashish Chakravarty
Built SLAM pipelines (ICP + KD-tree local mapping on CARLA point clouds) for a 20 cm localization gain, and led a 25-student RL & vision team across 3+ international competitions.
RISS Scholar, Jun–Aug 2024 · R-Pad Lab, CMU — with David Held, Zackory Erickson & Yufei Wang
Built an RL system that uses VLMs to generate reward functions from offline, unlabelled datasets. Achieved a 40%+ gain in success rate and SOTA 0.82 on a real-world assistive-dressing task in out-of-distribution settings.
Research Intern, Jan–Nov 2024 · with Sherry Yang & Bo Dai
Proposed VideoAgent to self-refine robotic video plans using pretrained VLM feedback and online replanning. Raised MetaWorld success 43.1% → 50%, iTHOR 31.3% → 34.2%, and +22% task acceptance in human evals on BridgeV2.
Gold Medal · Captain, IIT Kharagpur contingent · Nov–Dec 2024
Led the team to gold with an Active-SLAM + YOLO-World goal-detection pipeline, Hungarian task-agent matching over a sparse bipartite graph, and PRIMAL-2 with hindsight replay for map-agnostic multi-agent path planning.
B.Tech Thesis, Aug 2024 – May 2025 · advised by Aritra Hazra & Naveen Kumar Garg
Explored unsupervised pretraining for task-agnostic representations in multi-task RL; reproduced AVDC results on the impact of shared image-space representations for multi-task learning.
Gold Winner, Train-Offline-Test-Online (TOTO) Benchmark Competition @ NeurIPS 2023 Workshop
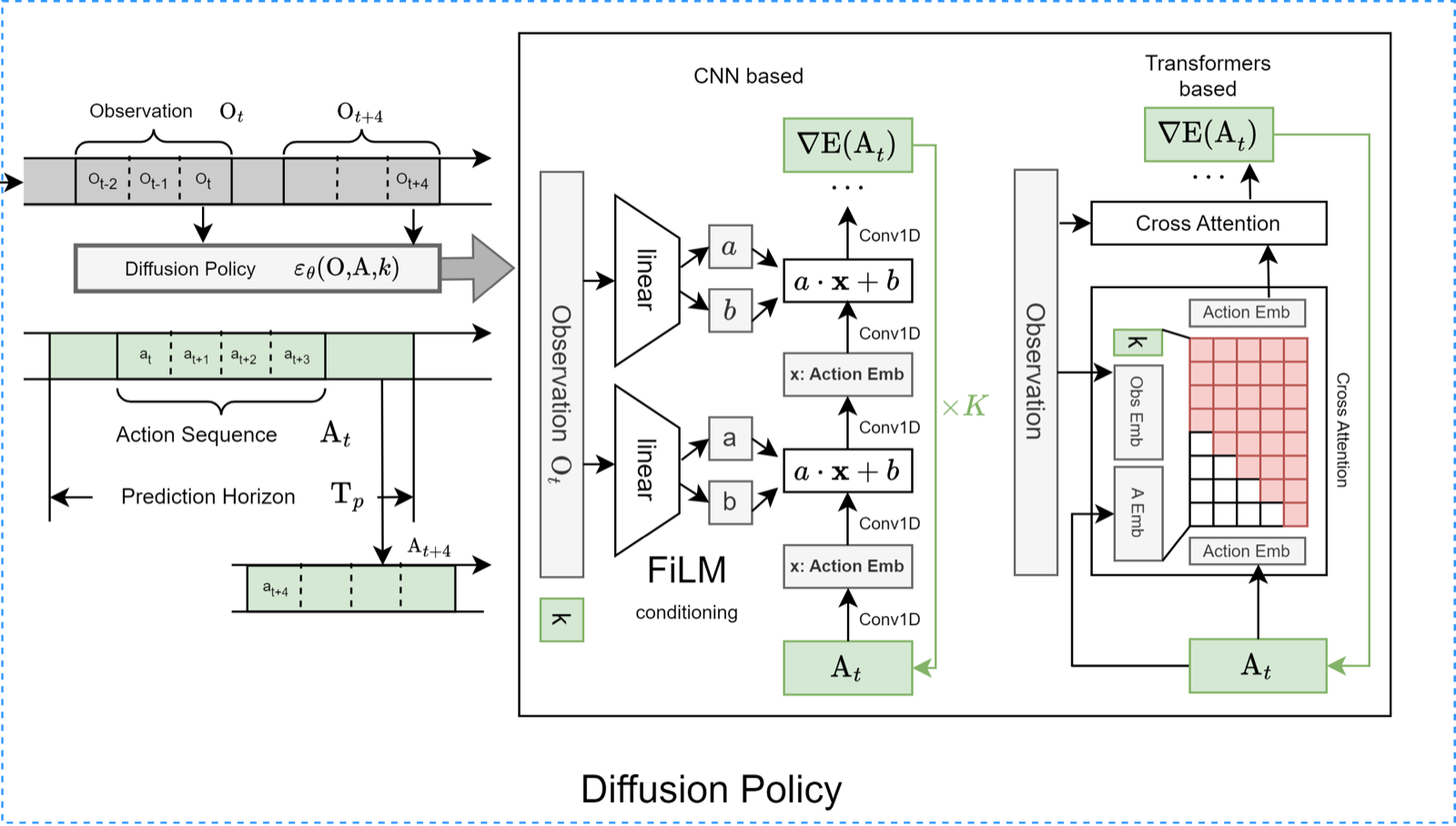
Robot learning tasks are extremely compute-intensive and hardware-specific. Thus the avenues of tackling these challenges, using a diverse dataset of offline demonstrations that can be used to train robot manipulation agents, is very appealing. The Train-Offline-Test-Online (TOTO) Benchmark provides a well-curated open-source dataset for offline training comprised mostly of expert data and also benchmark scores of the common offline-RL and behaviour cloning agents. In this paper, we introduce DiffClone, an offline algorithm of enhanced behaviour cloning agent with diffusion-based policy learning, and measured the efficacy of our method on real online physical robots at test time. This is also our official submission to the Train-Offline-Test-Online (TOTO) Benchmark Challenge organized at NeurIPS 2023. We experimented with both pre-trained visual representation and agent policies. In our experiments, we find that MOCO finetuned ResNet50 performs the best in comparison to other finetuned representations. Goal state conditioning and mapping to transitions resulted in a minute increase in the success rate and mean-reward. As for the agent policy, we developed DiffClone, a behaviour cloning agent improved using conditional diffusion.
IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) 2025 · LangRob Workshop @ CoRL 2024
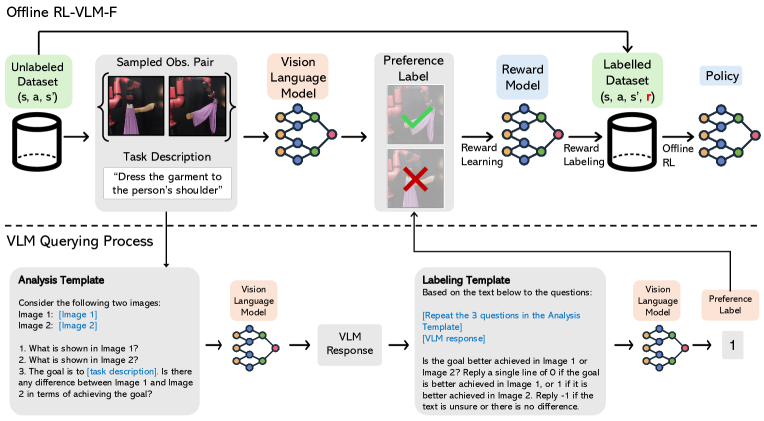
Offline reinforcement learning can enable policy learning from pre-collected, sub-optimal datasets without online interactions. This makes it ideal for real-world robots and safety-critical scenarios, where collecting online data or expert demonstrations is slow, costly, and risky. However, most existing offline RL works assume the dataset is already labeled with the task rewards, a process that often requires significant human effort, especially when ground-truth states are hard to ascertain (e.g., in the real-world). In this paper, we build on prior work, specifically RL-VLM-F, and propose a novel system that automatically generates reward labels for offline datasets using preference feedback from a vision-language model and a text description of the task. Our method then learns a policy using offline RL with the reward-labeled dataset. We demonstrate the system’s applicability to a complex real-world robot-assisted dressing task, where we first learn a reward function using a vision-language model on a sub-optimal offline dataset, and then we use the learned reward to employ Implicit Q learning to develop an effective dressing policy. Our method also performs well in simulation tasks involving the manipulation of rigid and deformable objects, and significantly outperform baselines such as behavior cloning and inverse RL. In summary, we propose a new system that enables automatic reward labeling and policy learning from unlabeled, sub-optimal offline datasets.
Spotlight, RL Beyond Rewards Workshop @ RLC 2025 · Spotlight, LAW Workshop (Bridging Language, Agent, and World Models) @ NeurIPS 2025
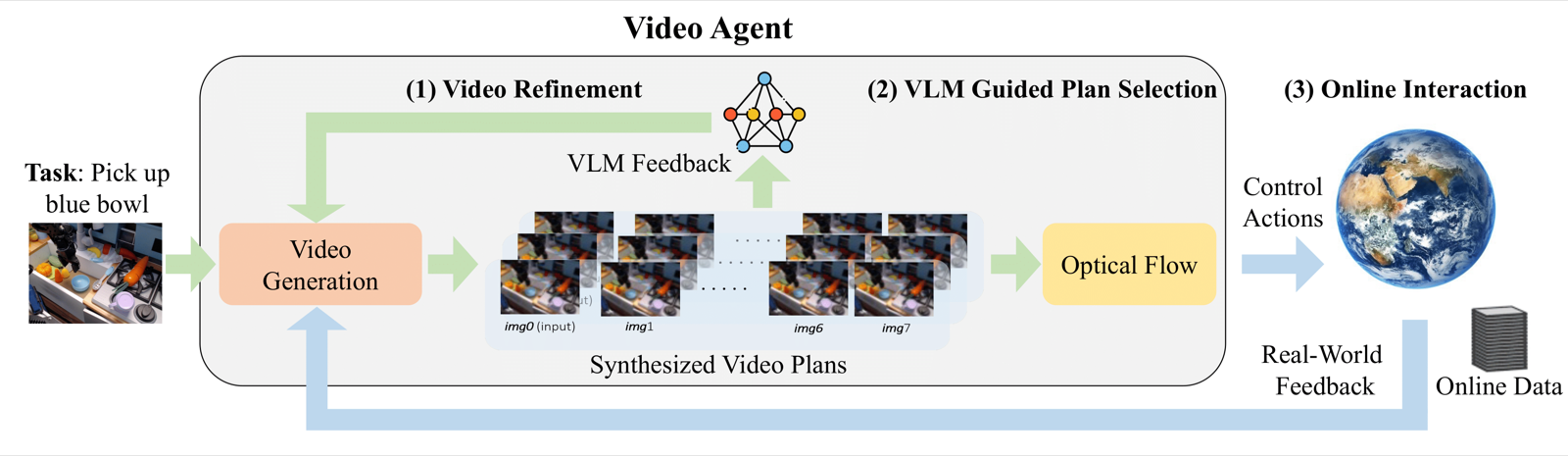
Video generation has been used to generate visual plans for controlling robotic systems. Given an image observation and a language instruction, previous work has generated video plans which are then converted to robot controls to be executed. However, a major bottleneck in leveraging video generation for control lies in the quality of the generated videos, which often suffer from hallucinatory content and unrealistic physics, resulting in low task success when control actions are extracted from the generated videos. While scaling up dataset and model size provides a partial solution, integrating external feedback is both natural and essential for grounding video generation in the real world. With this observation, we propose VideoAgent for self-improving generated video plans based on external feedback. Instead of directly executing the generated video plan, VideoAgent first refines the generated video plans using a novel procedure which we call self-conditioning consistency, utilizing feedback from a pretrained vision-language model (VLM). As the refined video plan is being executed, VideoAgent collects additional data from the environment to further improve video plan generation. Experiments in simulated robotic manipulation from MetaWorld and iTHOR show that VideoAgent drastically reduces hallucination, thereby boosting success rate of downstream manipulation tasks. We further illustrate that VideoAgent can effectively refine real-robot videos, providing an early indicator that robotics can be an effective tool in grounding video generation in the physical world.
Published:
Spoke at the Global Gathering event hosted by Venture Café Tokyo and RoboticsXTokyo on the robotics landscape in Japan and India, and how the two countries can collaborate for innovation and growth. Introduced the concept of “Jugaad” — a uniquely Indian approach to frugal innovation.
 16-867: Human-Robot Interaction (Fall 2026)
16-867: Human-Robot Interaction (Fall 2026)Graduate, Carnegie Mellon University, 2026